Open and Structured Content Models Workshop Recap
People consume government information in a variety of ways: through agency websites, of course, but increasingly through social media, search engines, and mobile apps, whether developed by agencies or third parties.
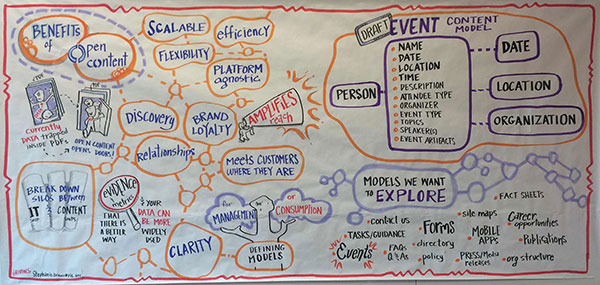
To make sure the information is available seamlessly, accurately, and consistently from one setting to another, more and more agencies are exploring the use of content models. Content models create a structure to tag content in a standardized way and free it from any single format or destination, such as a Web page or PDF file.
The Open and Structured Content Models Working Group, an interagency working group, has been exploring the approach for government since last year and they have created two open and structured content models—one for articles and one for events. They hosted a September workshop so agencies could hear from a few organizations who are already putting these ideas into practice. Attendees discussed how to build the case for the content model approach, how the models work in practice and how to implement the existing models.
SEC: Mission is Key to Open and Structured Content Models business case
While the working group created two content models and noted the reasons agencies should adopt them, there are a number of other information types that can be structured and modeled. For instance, the Securities and Exchange Commission (SEC) has been working on eXtensible Business Reporting Language, or XBRL—part of the family of interactive data reporting standards.
Walter Hamshcer, who is involved in the SEC XBRL effort, talked about his work on the 30 year XBRL project. Hamshcer noted that the best way to sell the structured data and content model approach is to focus on the data and content your organization “cares about most”—tangible parts of the mission space. In his experience, transparency regulators generally care about disclosure and his project has been working with structured data approaches with financial statement information.
From there, Hamscher warned, you still have to build and sell your case. It’s generally easier to build your case on existing data structures and metadata currently in use within the organization. In addition, the SEC business case included a cost benefit analysis, addressed the Paperwork Reduction Act and demonstrated that structured data approaches were valued by stakeholders.
An important soft skill when presenting the case for structured content models is talking the language of stakeholders when selling the idea. Hamscher said if there is an analogy that works for the group you’re speaking to, use it when explaining the new approach.
National Public Radio: How Open and Structured Content Models Work in Practice
For several years, NPR has embraced a digital strategy of Create Once, Publish Everywhere, or COPE and the organization has been an influence on the open and structured content models working group.
Jeremy Pennycook explained how COPE works in practice to support not only the websites of NPR and its affiliates, but also the creation of new apps. Pennycook is product manager for NPR One, an audio app that combines hand-curation and machine learning to give listeners a custom stream of radio stories tailored to their interests.
In creating the app, NPR tried to keep it simple for users. “What we don’t want to do is present users with 1,000 different options,” Pennycook said. “It’s essentially a magic box that cool stories come out of.” The NPR One team also wanted to pull content seamlessly from other stations (such as local public radio affiliates) without listeners noticing the difference.
Finally, NPR uses data generated by the app to tailor content. For example, the app tracks whether users complete stories, skip them, or rate them, and that information helps shape what next appears in the stream.
The COPE strategy makes apps like this possible, Pennycook said. The app uses existing information already tagged to NPR’s content to present it in new ways. “You’re not creating a page, you’re creating a unit of content, and a page is something that might display it,” he explained.
That tagged information, or metadata, gives the content a structure distinct from its display. The same item can appear on different pages of the NPR website (such as the show that aired it, a topic page, or a blog), in an app, or on an affiliate website. Metadata such as the title and other details may even appear on your car radio.
Pennycock said it was important that:
- Content be independent from where or how it appears. By separating content from display, you can remain flexible and adapt your content in the future.
- Content should be portable. You need the ability both to capture structured content and to extract it so you can use it. “It’s not enough to just have it sitting in a database somewhere; you actually need a pipeline to be able to get it out,” Pennycook said.
Implementing the Existing Open and Structured Content Models
A number of agencies, including NASA, National Cancer Institute and Department of Health and Human Services, discussed implementing the article and event models at the event. There were so many questions that the conversations have been moved to the working group’s space on GitHub. In fact, the Department of Health and Human Service, posted their draft mock-up of their approach to the article model.
If you are interested in joining the effort, check out the issues on GitHub and contact Jacob Parcell to join the working group and engage with other federal agencies implementing this approach.
Hannah Gladfelter Rubin is an Information Research Specialist with the Congressional Research Service at the Library of Congress. The views expressed herein are those of the author and are not presented as those of the Congressional Research Service or the Library of Congress.

